


Are Most Claimed Psychiatric Diagnoses False?
Another take on over-diagnosis

This essay might be read in conjunction with Awais Aftab’s recent pieces on over-diagnosis. It makes a strong claim, one I hope is supported and thought-provoking. Some readers will notice similarities to a well-known article by John Ioaniddis.
In this essay, I argue that most claimed psychiatric diagnoses are false. By most, I mean more than half. By claimed psychiatric diagnoses, I mean all the instances where a person is told by a licensed healthcare professional that they have a mental disorder. By false, I mean that the person does not actually have a mental disorder, has a diagnosis different than the one they are given, or has multiple labels when only one is accurate. This is not a debate about the definition of mental illness, and it accepts DSM/ICD diagnoses on their own terms.
Diagnostic interviews, like medical tests and scientific experiments, return results that are true-positive (a hit), false-positive (a false alarm), true-negative (a rule-out), or false-negative (a miss).The problem is that we can’t distinguish the true-positives from the false-positives. But we can calculate a “positive predictive value,” the chance a claimed result is actually true. My argument rests on the difficulty of achieving a positive predictive value over 50% for most mental health diagnoses in most real-world clinical contexts.1

Of course, we can’t know the true prevalence of mental disorders, since psychiatry doesn’t really have gold-standard diagnostic tests. Studies often use expert clinical interviews as the assumed standard, and we do have rigorous assessments such as the Structured Clinical Interview or Mini International Neuropsychiatric Interview. These are taken as definitive, but ultimately we use an interview to assess the result of another interview. If this sounds more like replication than verification, I think you’re right. In fact, this dynamic places psychiatry in the same position as all scientific research, which also lacks an objective “truth” against which to check results.
Not coincidentally, our clinical work is subject to the same problems as some scientific fields. Facing incentives to find a diagnosis, we unwittingly end up using tactics much like the various forms of p-hacking. During an evaluation, we have many degrees of freedom to tweak criteria, ignore symptoms that don’t fit, stop collecting data at any point, and lower the bar for a disorder. We assess for multiple conditions without adjusting the significance threshold. We even have a form of publication bias, as new diagnoses go on a patient’s problem list while negative results stay buried.
The false-positives problem matters. It matters for patients, treatment effectiveness and public policy. It matters for the reputation of psychiatry, due for a public backlash. It matters for the science of mental illness, still marked by boom-and-bust cycles, poor replication, and lack of progress in understanding the conditions we treat. Improving the situation requires understanding its causes.
The accuracy of a result depends on its plausibility
Before an interview gets going, we have a set of possible conditions in mind. The patient’s presenting concern provides some direction, but someone with “depression” might have major depressive disorder, persistent depressive disorder, generalized anxiety or social anxiety, bipolar 2 disorder, borderline or avoidant or dependent personality, adjustment disorder, substance use, a medical condition, or no mental illness at all. The weight given to each of these possibilities is a critical but underdetermined question; one I’ve never seen quantified or made explicit in any way.
Regardless, we start with a few major hypotheses and some less likely alternatives. Unless we’re planning on making multiple diagnoses (are we?), greater likelihood for one condition crowds out others. The interview and exam is then a set of tests, turning the initial probability for each diagnostic hypothesis into a binary finding: is the condition present or not?
The chance this conclusion is true depends on the chance of it being true beforehand, the thoroughness of the evaluation, and the strictness of the evaluation.
The initial chance relates to the disorder's prevalence, or how common it is for that setting and demographic group. There’s no getting around assumptions here.
Thoroughness equates to test sensitivity, or the ability to find true-positives. Does the clinician follow leads, ask widely about symptoms, and review past as well as current concerns?
Strictness equates to specificity, or the true-negative rate. Does the clinician actually go through criteria and require evidence of impairment? How high is the bar for disorder set?
Thorough evaluations are less likely to miss a diagnosis when it exists, while strict evaluations are less likely to label a patient based on wisps of evidence. There is usually a trade-off between them.
Here’s how the numbers shake out for a condition at 30% prevalence and evaluation with 90% sensitivity and specificity.2
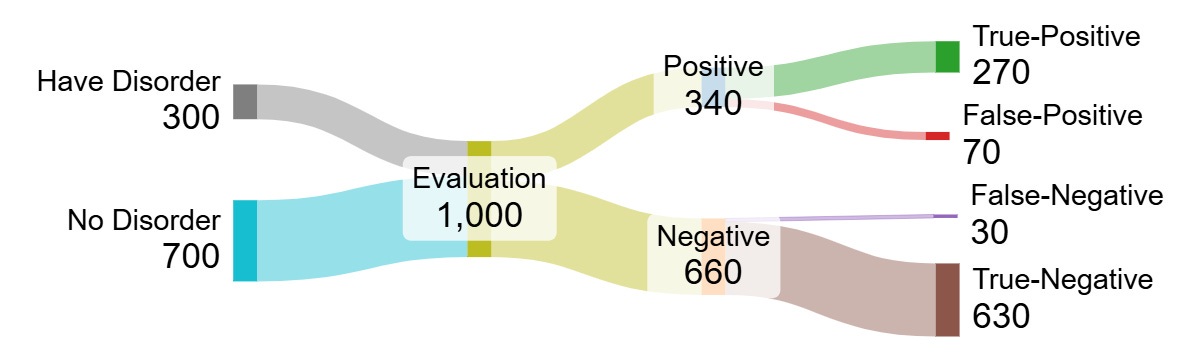
On the other hand, when a disorder is rare, most positive findings will be false. The classic example is the large number of false-alarm mammograms when screening young women who are unlikely to have breast cancer. When the same evaluation looks for a condition with only 3% prevalence, things turn out different:

An interesting corollary is that greater cultural emphasis on mental health makes it less likely that claimed disorders are true. Trends that encourage individuals to seek out care will lower the pre-evaluation probability for all conditions, as more healthy people undergo assessment. Lower prevalence necessarily decreases the positive predictive value, i.e. the percentage of true diagnoses. As a result, diagnostic accuracy has likely been declining for years. However, low starting probability is just one cause of false findings.
Typical Evaluations are Underpowered to Distinguish Between Common Conditions
Diagnoses produce different patterns in clinical data. Some stand out, like florid mania or contamination OCD, because the clinical presentation is distinctive. They are hard to miss. But many have overlapping symptoms such as impaired sleep, fatigue, poor concentration, or anxiety; these overlap with normal experience as well. For example, MDD and Generalized Anxiety Disorder are diagnosed together in 30-50% of cases, and symptom scales show about a .65 correlation. Social anxiety, panic disorder, substance use, and personality disorders also overlap a lot. These are the most common disorders!
Teasing these diagnoses apart - assuming they are actually different - is like detecting a signal buried in noise, or performing a study on a small effect size. When there is little difference between two conditions, or between a disorder and normal experience, it takes a very thorough evaluation to distinguish them, perhaps involving multiple visits, reviewing old records, and talking to family.3 This is rarely practical and likely impossible in many cases.
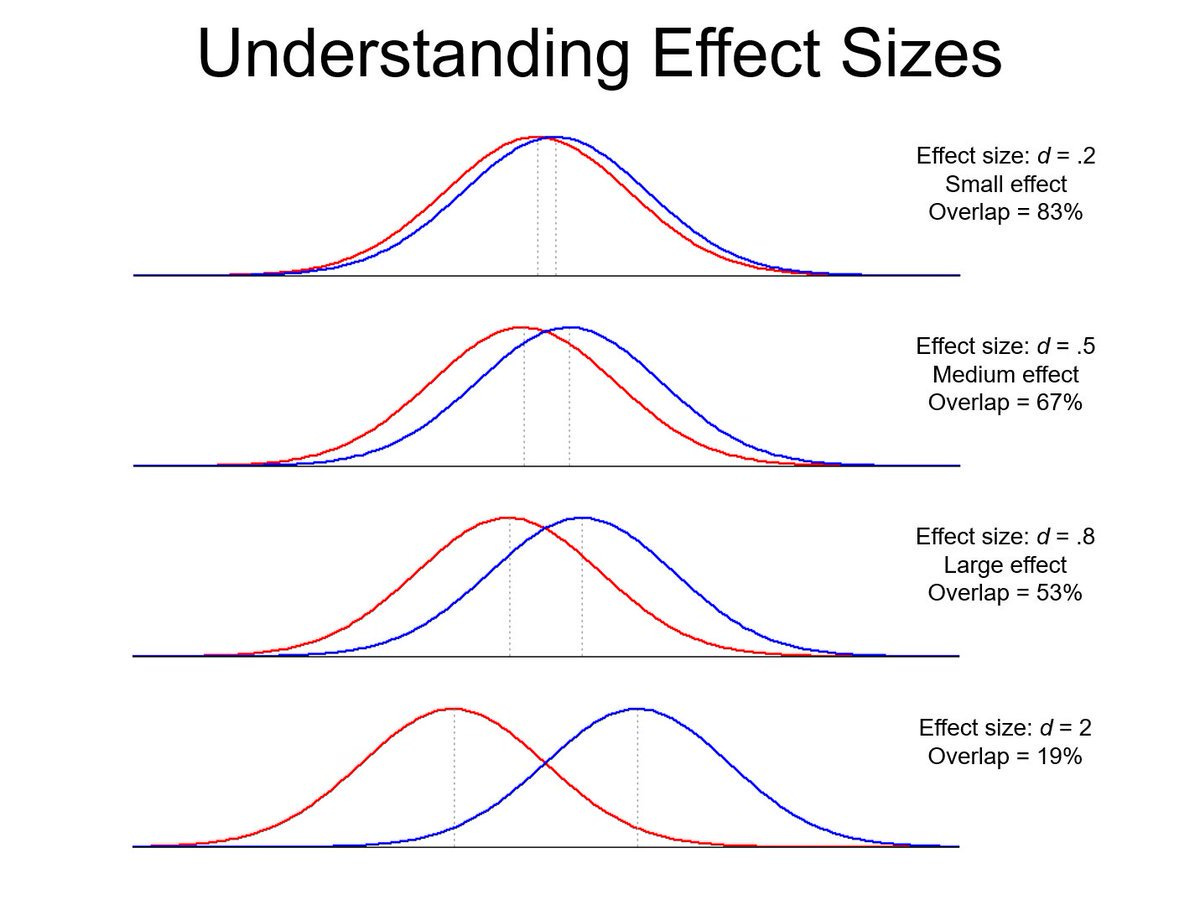
As a result, we often see patients whose symptoms seem to fit multiple diagnoses. In these cases, the options are:
Pick one condition as the best explanation for the patient’s symptoms
Withhold judgment
Diagnose all the conditions for which the patient “meets criteria.”
Pick a vague label like Unspecified Mood Disorder or Unspecified Anxiety.
Option 1 is supposedly what the DSM and ICD authors intended. Option 2 seems most scientifically valid, but both patients and payers expect a diagnosis. Options 3 and 4 are the usual practice, and so patients with an ambiguous presentation end up with several diagnoses from a single visit, or different diagnoses from a series of assessments. For example, if the observable differences between typical depression, anxiety, and ADHD are small, patients with this constellation of concerns will receive different labels at different times due to chance variation alone.
In general, the less specific or milder the presentation, the less likely the diagnosis is to be true. A scientific literature consisting of underpowered studies will be inconsistent and misleading, and the same is true for a set of clinical evaluations. It might be that one or more conditions is actually present, and the others are misdiagnosed. It might also be that none of them are true, and any claimed conditions are diagnostic noise. Underpowered assessments miss real conditions, but they also overstate apparent differences and report more false-positives. This problem worsens as the skill of clinicians decreases.
The Accuracy of a Conclusion Depends on How You Got There
Some assessments are better than others. We can model different values for thoroughness, strictness, prevalence, and the resulting Positive Predictive Value. The chart below represents the performance of three different clinicians evaluating a patient for a common condition like MDD or GAD, from best case to pretty good to mediocre. For simplicity, sensitivity and specificity are equal in each case. As expected, the less rigorous an evaluation, the less likely a claimed diagnosis is true.

For a good psychiatrist doing a good interview in good conditions, the scenario of 85% sensitivity and 85% specificity (red line) seems fair. This is consistent with research on how often different clinicians arrive at the same diagnosis for the same patient.4 It is also better than common symptom questionnaires. When a good psychiatrist evaluates a patient for “depression,” and we assign MDD a generous 40% probability, and the patient is duly diagnosed with MDD, the chance they have MDD is 79%. In other words, under favorable assumptions, a fifth of patients told they have MDD do not actually have it.
However, most mental disorders are not diagnosed by psychiatrists or psychologists but by non-specialist physicians or therapists with less training. Time and competing priorities are major constraints. A shorter interview, performed by a less skilled clinician, will have lower sensitivity and specificity. This is represented by the 75% scenario in yellow.5 A similar patient diagnosed with MDD by their internist has a 67% chance of truly having MDD, so one-third do not.
These results assume a high suspicion for MDD to start with, which may or may not be right, but it's definitely an assumption! Positive predictive value plummets at lower prevalence. At 20% likelihood, the value of an MDD diagnosis is 59% from a good psychiatrist and 43% from our hypothetical internist. This is before allowing for other factors influencing the diagnostic process.
Every Observation is Theory-Laden, but Some Are More Theory-Laden Than Others
A psychiatric interview is more like a negotiation than a brain scan. Both sides have an agenda, and the hope is to arrive at a mutually agreeable label. At the same time, the greater the flexibility in assessment, the greater the potential for transforming a “negative” result into a “positive.” In short, diagnostic performance is subject to various forms of bias, most of which increase the number of false diagnoses. For example:
Clinician preference for certain conditions. We all know people who try to diagnose every patient with bipolar disorder, PTSD, or some other hobbyhorse.
Patient preference for certain diagnosis. Most patients read an article or took an online quiz or tried their roommate’s ritalin. They’re here to placate their spouse. Their framing of the problem influences the initial odds assigned to each condition. They may selectively report or distort their symptoms to obtain a particular diagnosis.
Prejudice against certain diagnoses. Patients dislike being told they have a personality disorder or a substance use disorder. We dance around this by offering more palatable alternatives or diagnosing two conditions to soften the blow.
Fudging edge cases to meet criteria or severity threshold. If a patient has four instead of five depressive symptoms, but they seem very distraught, what would you do? It’s hard to tell a tearful person asking for help that they don’t technically have major depression.
Use of Unspecified Depression and Unspecified Anxiety. These exist for patients who don’t quite fit diagnostic criteria. They imply a level of uncertainty only apparent to other psychiatrists; the patient’s take-home is still “the doctor said I have depression.”
One way of thinking about this is that diagnoses have different thresholds. Most psychiatrists want to be pretty sure before telling a college student they have schizophrenia. But for common conditions, the downside of a false positive seems small, especially if we think treatment will help, so the bar for diagnosis ends up lower.6 How certain do you need to be to diagnose someone with panic disorder?
The cumulative effect is more positives as a whole, both true and false, lowering the discriminatory value of a diagnosis. We can model this bias as a factor that increases sensitivity and reduces specificity:

The overall impact of bias is substantial for two reasons. First, people with minimal symptoms don’t seek help, and severe illness is rare, so edge cases make up a large portion of individuals coming to clinical attention. Second, small shifts in threshold have a large effect. By analogy, moving the cut-off for the PHQ-9 depression scale (0 to 27 points) from 10 to 8 reduces the positive predictive value from ~59% to 49%.7
Consider our 40% biased general practitioner, green line above, assessing 100 patients for “depression,” 20 of whom actually have MDD. They will diagnose 61 people with MDD, 17 true and 44 false, or 72% false-positives. Is this realistic? Well, this meta-analysis concludes that “for every 100 unselected cases seen in primary care, there are more false positives (n=15) than either missed (n=10) or identified cases (n=10).” This is an empirical finding of a 60% false-positive rate, so I think we’re in the ballpark.
Hitting a bullseye is easy when the wall is covered in dart boards.
Multiple clinicians may evaluate the same person over the course of a year or two, for instance when a patient sees a primary care physician, psychiatrist, and therapist, they present to both a hospital and clinic, the patient opts for a new clinician, their insurance network changes, etc. In addition, clinicians are trained to screen for multiple conditions separate from whatever the patient wants to talk about. A patient presenting with depression will also be asked about panic attacks, chronic worry, psychosis, OCD, trauma, etc. In essence, rather than testing a single hypothesis, the interview tests multiple secondary hypotheses.
Both factors contribute to a multiple comparisons problem in mental health. When multiple tests occur, the odds of some positive result leap up, purely due to chance.
In an experiment testing 5 hypotheses, at significance level of α = 5%, the chance to obtain at least one significant result is 23%.
In a clinical setting, at a false-positive rate of 15%, a patient who sees 3 independent clinicians has a 39% chance of one false-positive diagnosis.
If each clinician also “tests” for three conditions, the chance of a false-positive rises to 77%.
In other words, as a patient sees more clinicians, and each clinician looks for more conditions, the positive predictive value of any particular diagnosis drops. We should be exceedingly skeptical of, for instance, an incidental claim of bipolar disorder for a patient who presented with anxiety. This can also be modeled:

A notable implication is that the more popular a diagnostic entity, the less likely individual findings are to be true. When a particular condition garners increased attention, more individuals seek out evaluations for that condition. As above, the value of isolated findings decreases when many evaluations are performed for the same condition. This contributes to the familiar cycle of hype and disillusionment.
Most Diagnoses Are False for Most Evaluations
In the described framework, a Positive Predictive Value over 50% is difficult to achieve. Doing so effectively requires starting with high suspicion for the eventual diagnosis. This entails either placing a high weight on the patient’s chief complaint, which increases the impact of patient bias, or placing a high weight on the clinician’s assumptions, which increases the impact of clinician bias. An open-ended approach expands the number of candidate diagnoses, but this necessarily means lower pre-test probabilities for any given condition. As a patient sees more providers over time, and more diagnoses are considered, the chance of hitting upon the correct diagnosis goes up, but so does the chance of one or more incorrect diagnoses.
One exception is “classic” presentations, where it is obvious the patient has a mental health condition, and the symptoms are distinct enough that only one or two diagnoses could fit the bill. This is equivalent to performing studies on phenomena with large effect sizes. As in most fields, this is relatively rare and has become increasingly so as the number of such cases is diluted by more people seeking care.

To conclude that most claimed psychiatric diagnoses are false, it would need to be the case that scenarios with low predictive value outnumber those with high. I think this is true, but it’s hard to find data. It’s generally thought that half or more of mental health visits occur in primary care. Mental health concerns take up 15-20% of primary care visits, and there are 4.5x as many primary care providers as psychiatrists in the US. In addition, the most common psychiatric diagnoses are those closest to normal experience, where the threshold for disorder is most slippery. Finally, diagnostic bias is clearly a thing, though the magnitude is up for debate. I think it is substantial, based on regular encounters with patients who made it through a PhD program with supposedly undiagnosed ADHD, people with bipolar disorder who have never been manic, and people labelled with four or five conditions when one would do. But this is the weakest part of my argument.
Critiques
You have a bad model for a psychiatric interview.
This is the standard framework used to describe all medical diagnostic tests. We talk about the prevalence, sensitivity and specificity, and PPV (also Negative Predictive Value) for everything from EKGs to mammograms to symptom questionnaires. It includes elements of Null-Hypothesis Significance Testing, with type-1 and type-2 errors, and a Bayesian aspect of turning a prior probability into a posterior probability.
Perhaps we should be open-minded, gather as much data as possible, then look for patterns. This approach has the standard problem of induction; inevitably both clinicians and patients walk into an interview with interpretations in mind. You could argue that diagnosis is actually Inference to the Best Explanation. I like IBE, but in most cases there are multiple possible “explanations,” i.e. diagnoses, which is the whole problem.
Perhaps a diagnostic interview is actually a process of ruling out conditions rather than ruling in conditions. This fits well with the idea that hypotheses can never be proven, but only disproven. You can’t get away from assumptions about the baseline prevalence of each condition and still end up with several contending diagnoses.
Perhaps a diagnostic interview is a multistage process using different kinds of reasoning. You can certainly break it down, but at a high level I think something like my model holds. I would love to hear alternatives.
You made bad assumptions.
The choices I made for prevalence, sensitivity/specificity, and bias can all be questioned. I tried to show a range of values. Adopting more favorable assumptions will reduce the magnitude of the problem, but it is difficult to dismiss altogether. It’s certainly possible that only one-third of psychiatric diagnoses are false.
Doesn’t the same logic apply to many physical conditions in medicine?
Yes! There’s nothing unique about psychiatry or mental illness. There are many false diagnoses for back pain, IBS, migraines, and so on. The combination of subjective symptoms, flexible assessments, and a “what’s the harm to making a diagnosis” attitude will lead to false-positives in any context. We see fewer moral panics about the arthritis epidemic, though.
Does it really matter whether someone has GAD vs Panic Disorder, or MDD vs Persistent Depression? The treatment is the same.
Sometimes I think we should just call everything psychosis or neurosis and be done with it. But since we came up with all these labels, shouldn’t we apply them correctly? I think the reality is that 1) these categories capture something real and 2) much of the time we cannot reliably distinguish among them. This is due to bias, small effect sizes and low power as discussed above.
How to Improve the Situation
There are many ways to make psychiatric diagnosis more accurate. Most are boring, like “teach doctors to be more thorough.” Some impactful changes might be:
Train providers to specify starting probabilities for diagnoses. This makes conclusions far more meaningful. In addition, forcing a clinician to make predictions leads to better calibration and accuracy over time.
Change diagnosis to a prototype-matching model, rather than counting symptoms. With each condition defined as an illness prototype, the job of clinicians is to assess how closely a patient’s presentation matches the exemplar, or a defined subtype. The advantages are that this is how we think already, and it builds in something like a confidence level. For instance, a 5 out of 5 indicates a match “beyond a reasonable doubt” while 3 out of 5 is a partial match or “more likely than not.” This makes the uncertainty around most diagnoses more explicit.
Admit that there is a hierarchy of diagnoses, so that the presence of certain conditions obviates others. The DSM makes most conditions independent of each other, enabling multiple simultaneous diagnoses and creating the problem of comorbidity. There are notable exceptions, such as a diagnosis of bipolar disorder precluding major depressive disorder. This principle could be extended so that, for instance, having OCD precludes having GAD, MDD precludes panic disorder, and so on. This is an old and controversial idea. However, it is more consistent with medical practice and would reduce the number of false-positive diagnoses.
The concept of a diagnostic hierarchy brings up a broader point, one I keep returning to. There is no escaping assumptions, theory, interpretation, or whichever term you prefer. How common should a disorder be? Does it make sense that 20-30% of adults meet criteria for a psychiatric illness? Maybe, depending on your model of mental illness, but maybe not. The diagnostic landscape is the result of choices in how disorders are defined, how they relate to each other, and how they are assessed. Different choices would yield different outcomes. It is impossible to know a patient’s “true” condition, but we can always get better.
Missed diagnoses also occur, but I focus on false diagnoses because they garner less attention in the medical literature yet are of great cultural significance.
Specificity of 90% means a false-positive rate of 10%.
This is like increasing the sample size of a study.
Inter-rater reliability is quantified by kappa, basically the percentage of agreement while accounting for chance. For depression, reliability ranges from 0.5 to 0.75 and for psychosis it’s 0.6 to 0.8. Field trials for DSM-5 reported “Overall, five diagnoses were in the very good range (kappa=0.60–0.79), nine in the good range (kappa=0.40–0.59), six in the questionable range (kappa=0.20–0.39), and three in the unacceptable range (kappa values <0.20).” This opinion piece argues that realistic reliability for DSM diagnoses is kappa 0.4 to 0.6.
If a 25% false-positive rate seems high, consider that many civil lawsuits in the US are decided on the basis of “preponderance of evidence,” i.e. more likely than not, i.e. 51%.
We accept a lower specificity, or higher alpha.
Assuming 20% prevalence, PHQ-9 score of 8 has .95 sensitivity and .75 specificity per the review.
This is top-notch stuff! And damn, I think you are right. I’ve suspected so for a while but didn’t quite know how to articulate it. I’ve been thinking about this problem in recent years from the angle of “non-specific psychopathology” as discussed in a 2023 paper by Peter Zachar: https://onlinelibrary.wiley.com/doi/10.1002/wps.21043
Your post adds new consideration to this. I’ll try to articulate my own thoughts on how we can navigate this mess. I love your idea of assigning confidence/probability ratings to diagnoses. This is something I’ve doing informally when I’m giving an official diagnosis for various reason but I am highly uncertain or have low confidence in it’s applicability.
As I read this, I was thinking of restacking (? Is that the word) a paragraph, but then I read more and I wanted to restack that, and that feeling kept going throughout this piece. Definitely one of the best I have read here.
It has been something I have been sensing more and more as I have more years under my belt, but you articulated it much better than I ever could have - my sense that, even as a psychiatrist, most psychiatric diagnoses are false.
You hinted at many of the biases leading to that result, from individual (clinician inexperience, or “pet diagnoses”), to systemic (needing a diagnosis for billing reasons). Ultimately the whole system is set up to diagnose, which compounds the problem.